")
Feature Scaling is a technique to standardize the independent features present in the data in a fixed range. It is performed during the data pre-processing to handle highly varying magnitudes or values or units. If feature scaling is not done, then a machine learning algorithm tends to weigh greater values, higher and consider smaller values as the lower values, regardless of the unit of the values.
Example: If an algorithm is not using feature scaling method then it can consider the value 4000 meter to be greater than 6 km but that’s actually not true and in this case, the algorithm will give wrong predictions. So, we use Feature Scaling to bring all values to same magnitudes and thus, tackle this issue.
Techniques to perform Feature Scaling
Consider the two most important ones:
• Min-Max Normalization: This technique re-scales a feature or observation value with distribution value between 0 and 1.
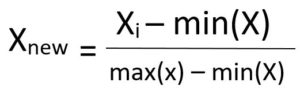
• Standardization: It is a very effective technique which re-scales a feature value so that it has distribution with 0 mean value and variance equals to 1.

Download the dataset:
Go to the link and download Data_for_Feature_Scaling.csv
Country No of years lived Income Purchased
France 54 82000 No
Spain 37 58000 Yes
Germany 40 64000 No
Spain 48 71000 No
Germany 50 2000 Yes
France 45 68000 Yes
Spain 88 62000 No
France 58 89000 Yes
Germany 60 93000 No
France 47 77000 Yes
Below is the Python Code:
# Python code explaining How to
# perform Feature Scaling
""" PART 1
Importing Libraries """
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Sklearn library
from sklearn import preprocessing
""" PART 2
Importing Data """
data_set = pd.read_csv('G:IITKMLData_for_Missing_Values.csv')
data_set.head()
# here Features - No of years lived and Income columns
# are taken using slicing
# to handle values with varying magnitude
x = data_set.iloc[:, 1:3].values
print ("nOriginal data values : n", x)
""" PART 4
Handling the missing values """
from sklearn import preprocessing
""" MIN MAX SCALER """
min_max_scaler = preprocessing.MinMaxScaler(feature_range =(0, 1))
# Scaled feature
x_after_min_max_scaler = min_max_scaler.fit_transform(x)
print ("nAfter min max Scaling : n", x_after_min_max_scaler)
""" Standardisation """
Standardisation = preprocessing.StandardScaler()
# Scaled feature
x_after_Standardisation = Standardisation.fit_transform(x)
print ("nAfter Standardisation : n", x_after_Standardisation)
Output :
Original data values :
[[ 54 82000]
[ 37 58000]
[ 40 64000]
[ 48 71000]
[ 50 2000]
[ 45 68000]
[ 88 62000]
[ 58 89000]
[ 60 93000]
[ 47 77000]]
After min max Scaling :
[[0.33333333 0.87912088]
[0. 0.61538462]
[0.05882353 0.68131868]
[0.21568627 0.75824176]
[0.25490196 0. ]
[0.15686275 0.72527473]
[1. 0.65934066]
[0.41176471 0.95604396]
[0.45098039 1. ]
[0.19607843 0.82417582]]
After Standardisation :
[[ 0.09536935 0.63723471]
[-1.15176827 -0.35585835]
[-0.93168516 -0.10758508]
[-0.34479687 0.18206706]
[-0.1980748 -2.67307548]
[-0.56487998 0.05793043]
[ 2.58964459 -0.19034284]
[ 0.38881349 0.92688685]
[ 0.53553557 1.09240236]
[-0.41815791 0.43034032]]