")
In linear regression, the model targets to get the best-fit regression line to predict the value of y based on the given input value (x). While training the model, the model calculates the cost function which measures the Root Mean Squared error between the predicted value (pred) and true value (y). The model targets to minimize the cost function.
To minimize the cost function, the model needs to have the best value of ?1 and ?2. Initially model selects ?1 and ?2 values randomly and then itertively update these value in order to minimize the cost function untill it reaches the minimum. By the time model achieves the minimum cost function, it will have the best ?1 and ?2 values. Using these finally updated values of ?1 and ?2 in the hypothesis equation of linear equation, model predicts the value of y in the best manner it can.
Therefore, the question arises – How ?1 and ?2 values get updated ?
Linear Regression Cost Function:
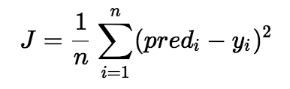
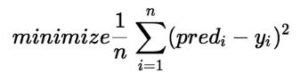
Gradient Descent Algorithm For Linear Regression


-> ?j : Weights of the hypothesis.
-> h?(xi) : predicted y value for ith input.
-> j : Feature index number (can be 0, 1, 2, ......, n).
-> ? : Learning Rate of Gradient Descent.
We graph cost function as a function of parameter estimates i.e. parameter range of our hypothesis function and the cost resulting from selecting a particular set of parameters. We move downward towards pits in the graph, to find the minimum value. Way to do this is taking derivative of cost function as explained in the above figure. Gradient Descent step downs the cost function in the direction of the steepest descent. Size of each step is determined by parameter ? known as Learning Rate.
In the Gradient Descent algorithm, one can infer two points :
If slope is +ve : ?j = ?j – (+ve value). Hence value of ?j decreases.
If slope is -ve : ?j = ?j – (-ve value). Hence value of ?j increases.
The choice of correct learning rate is very important as it ensures that Gradient Descent converges in a reasonable time. :
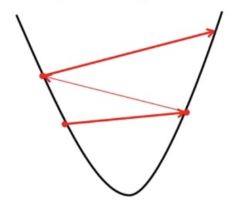
If we choose ? to be very large, Gradient Descent can overshoot the minimum. It may fail to converge or even diverge.
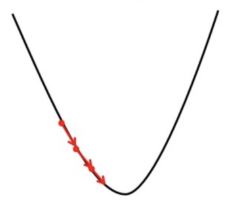
If we choose ? to be very small, Gradient Descent will take small steps to reach local minima and will take a longer time to reach minima.
No Comments