")
Using Linear Regression, all predictions >= 0.5 can be considered as 1 and rest all < 0.5 can be considered as 0. But then the question arises why classification can’t be performed using it?
Problem –
Suppose we are classifying a mail as spam or not spam and our output is y, it can be 0(spam) or 1(not spam). In case of Linear Regression, hθ(x) can be > 1 or < 0. Although our prediction should be in between 0 and 1, the model will predict value out of the range i.e. maybe > 1 or < 0.
So, that’s why for a Classification task, Logistic/Sigmoid Regression plays its role.
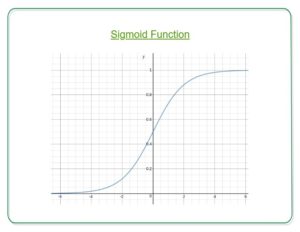
h_{Theta} (x) = g (Theta ^{T}x) z = Theta ^{T}x g(z) = frac{1}{1+e^{-z}}
Here, we plug θTx into logistic function where θ are the weights/parameters and x is the input and hθ(x) is the hypothesis function. g() is the sigmoid function.
It means that y = 1 probability when x is parameterized to θ
To get the discrete values 0 or 1 for classification, discrete boundaries are defined. The hypothesis function cab be translated as
Decision Boundary is the line that distinguishes the area where y=0 and where y=1. These decision boundaries result from the hypothesis function under consideration.
Understanding Decision Boundary with an example –
Let our hypothesis function be
Then the decision boundary looks like
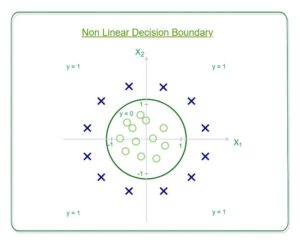
Let out weights or parameters be –
So, it predicts y = 1 if
And that is the equation of a circle with radius = 1 and origin as the center. This is the Decision Boundary for our defined hypothesis.